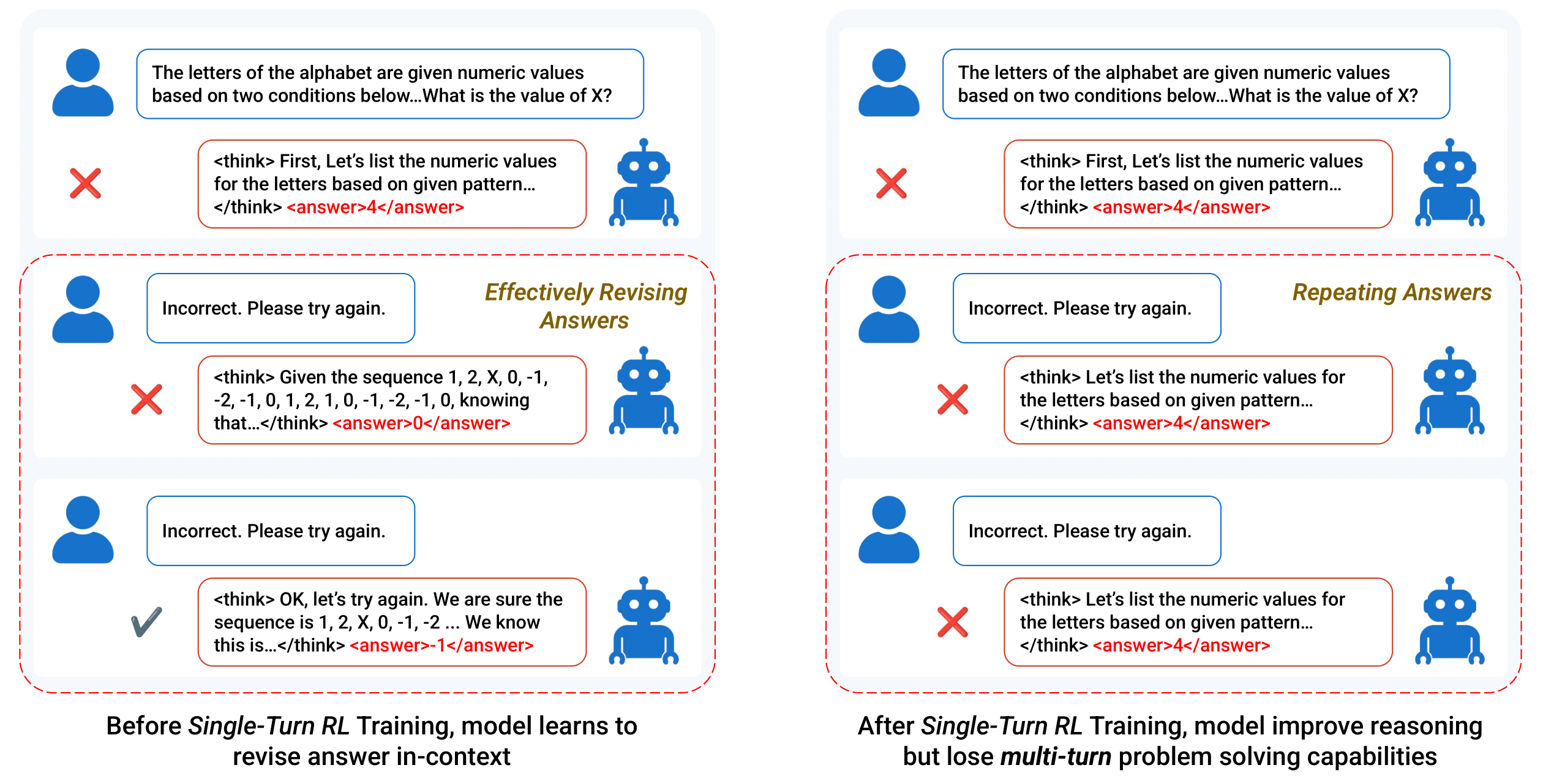
Current RL methods for LLMs focus on single-turn optimization, but struggle with multi-turn reasoning where models must revise answers based on feedback. We introduce Unary Feedback as Observation (UFO), a simple approach that trains models using minimal feedback like "try again" to improve iterative problem solving. UFO enhances multi-turn reasoning accuracy by up to 14% while preserving single-turn performance, enabling better adaptation to user feedback across multiple interaction rounds.
We address the challenge that single-turn reinforcement learning (RL) often fails to endow language models with multi-turn reasoning abilities, leading to repetitive and unadaptive responses. Our approach, Unary Feedback as Observation (UFO), reformulates multi-turn problem solving as a Markov Decision Process (MDP) using only static single-turn datasets and minimal feedback.
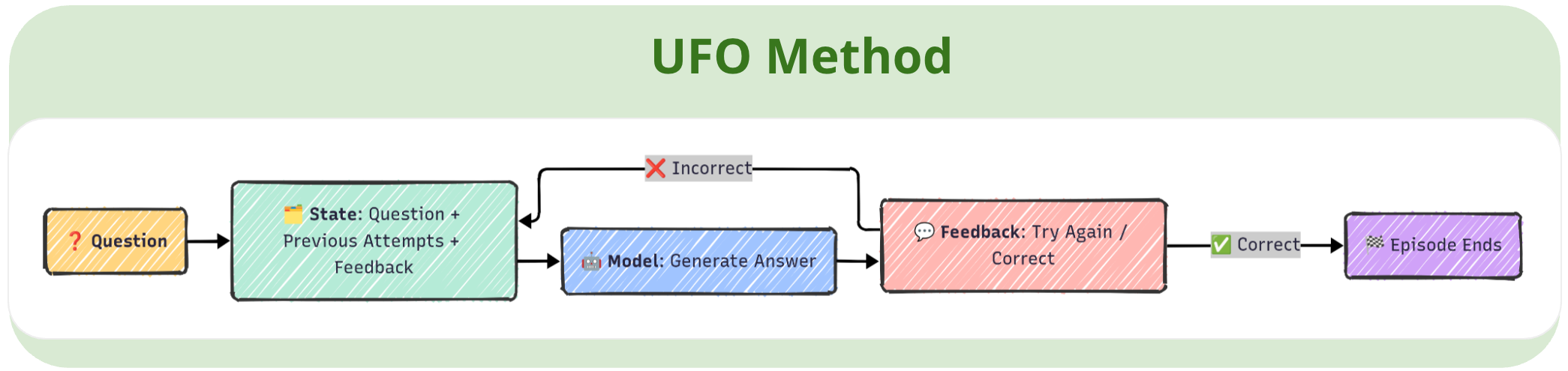
In UFO, the model interacts over multiple turns, receiving only negative feedback (e.g., "Try Again") after incorrect answers. The observation at each step concatenates the original question, all previous attempts, and their feedback, requiring the model to revise its reasoning based solely on a history of failed attempts. This design enables multi-turn training without the need for dense supervision or tool-augmented environments.
We optimize the model using Proximal Policy Optimization (PPO), with two key reward shaping strategies: reward decay (to encourage early success) and a repetition penalty (to promote answer diversity). This framework allows the model to develop revision-aware, context-sensitive reasoning strategies, unlocking robust multi-turn capabilities from static datasets and minimal supervision.
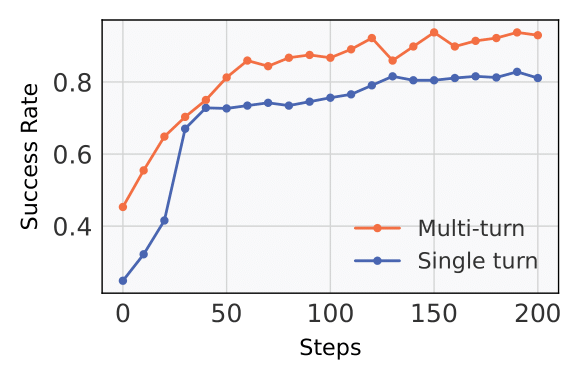
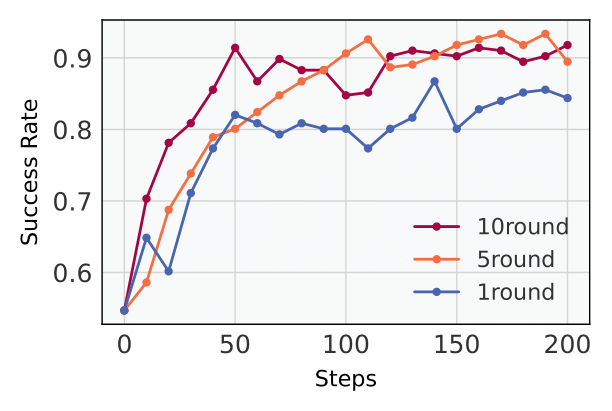
We compare our method UFO against a single-turn PPO-trained model using parallel sampling. For each problem, the baseline generates k independent responses in parallel and is evaluated using standard Pass@k metric. In contrast, our multi-turn model generates responses sequentially with unary feedback after each attempt, and is evaluated using both Succ@k and AvgTurns. Success is recorded if any of the k responses is correct. We also conduct ablation studies with different maximum interaction turns (Tmax) to further analyze the effect of multi-turn training.
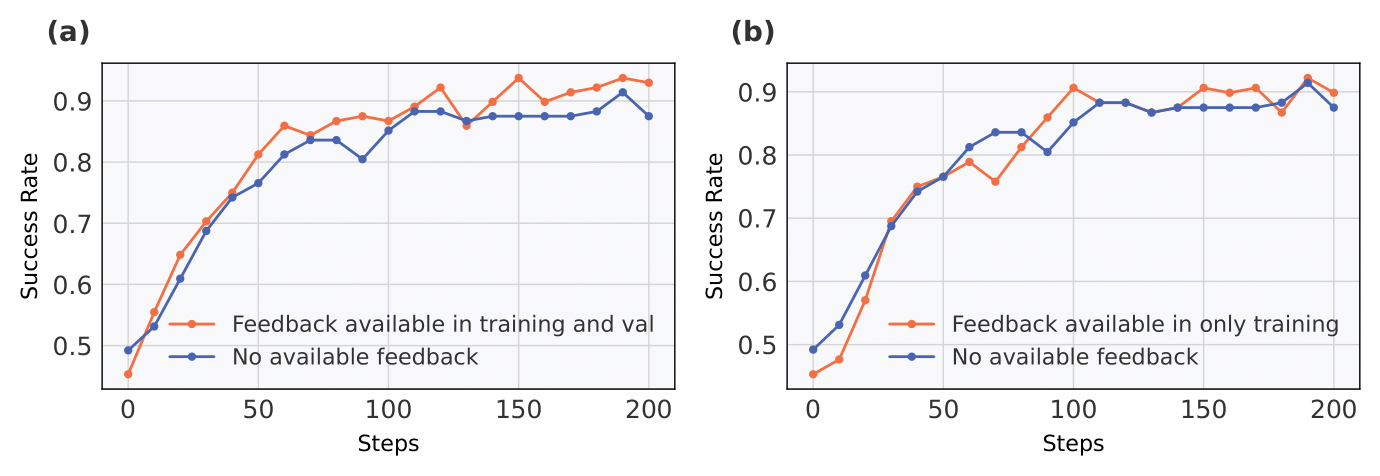
To further investigate the role of unary feedback, we compare model performance under different feedback availability conditions. In scenario (a), unary feedback is provided during both training and validation phases, while in scenario (b), unary feedback is available only during training but not at validation. The results show that access to unary feedback during both phases substantially improves validation success rate. In contrast, providing unary feedback solely during training does not yield improvements, indicating that the benefit of unary feedback is contingent on its availability at inference time.
+14% success rate over single-turn PPO baseline
Benefits generalize to both multi-turn and single-turn inference
Best results with 5-turn training; more turns yield diminishing returns
Feedback in both training and validation is crucial for improvement
Feedback only in training phase does not help at inference
Exponential reward decay decreases the average number of actions required to solve problems by ~10%.
Encourages faster and more efficient problem solving
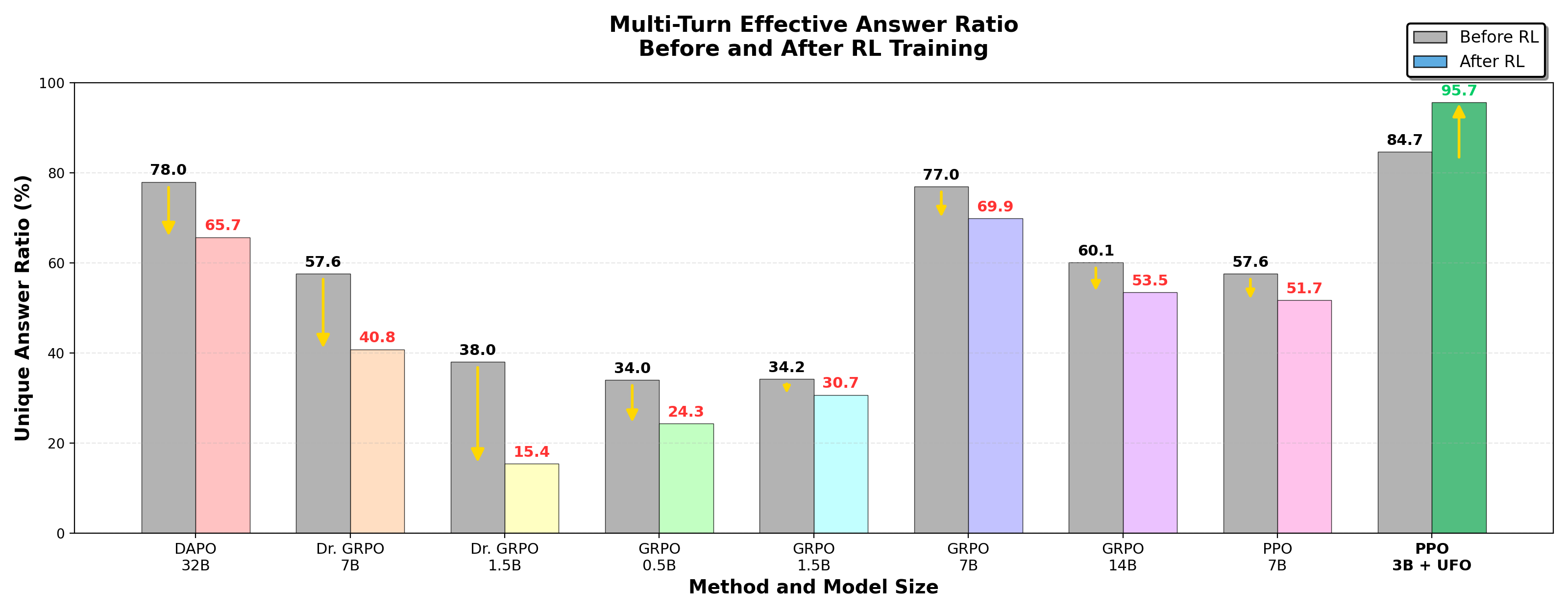
Non-repetitive answer ratio increases from 79.7% to 92.8%
Multi-turn RL with UFO encourages answer diversity and strengthens robustness
In this work, we identify a key limitation of conventional single-turn reinforcement learning: its tendency to undermine multi-turn reasoning by encouraging repetitive and superficial responses. To overcome this, we introduce Unary Feedback as Observation (UFO), a simple yet effective approach that incorporates minimal feedback into standard RL pipelines. UFO enables language models to recover and enhance both single-turn and multi-turn reasoning capabilities. Our experiments demonstrate a 14% improvement in multi-turn accuracy while maintaining single-turn performance. Furthermore, we show that integrating reward decay and repetition penalties fosters deeper reasoning, self-correction, and greater response diversity. Our method is lightweight, broadly applicable, and can be seamlessly integrated into existing RL training frameworks.
We thank the DeepSeek team for providing the DeepSeek-R1 model and early conceptual inspirations. We are grateful to the veRL team for their infrastructure support and the RAGEN team for their multi-turn RL framework.